ECCV 2012
Performance Capture of Interacting Characters with Handheld Kinects
Genzhi Ye, Yebin Liu, Nils Hasler, Xiangyang Ji,Qionghai Dai, Christian Theobalt
Tsinghua University Max-Planck Institute for Informatics
Abstract
We present an algorithm for marker-less performance capture of interacting humans using only three hand-held Kinect cameras. Our method reconstructs human skeletal poses, deforming surface geometry and camera poses for every time step of the depth video. Skeletal configurations and camera poses are found by solving a joint energy minimization problem which optimizes the alignment of RGBZ data from all cameras, as well as the alignment of human shape templates to the Kinect data. The energy function is based on a combination of geometric correspondence finding, implicit scene segmentation, and correspondence finding using image features. Only the combination of geometric and photometric correspondences and the integration of human pose and camera pose estimation enables reliable performance capture with only three sensors. As opposed to previous performance capture methods, our algorithm succeeds on general uncontrolled indoor scenes with potentially dynamic background, and it succeeds even if the cameras are moving.
[paper] [Slide]
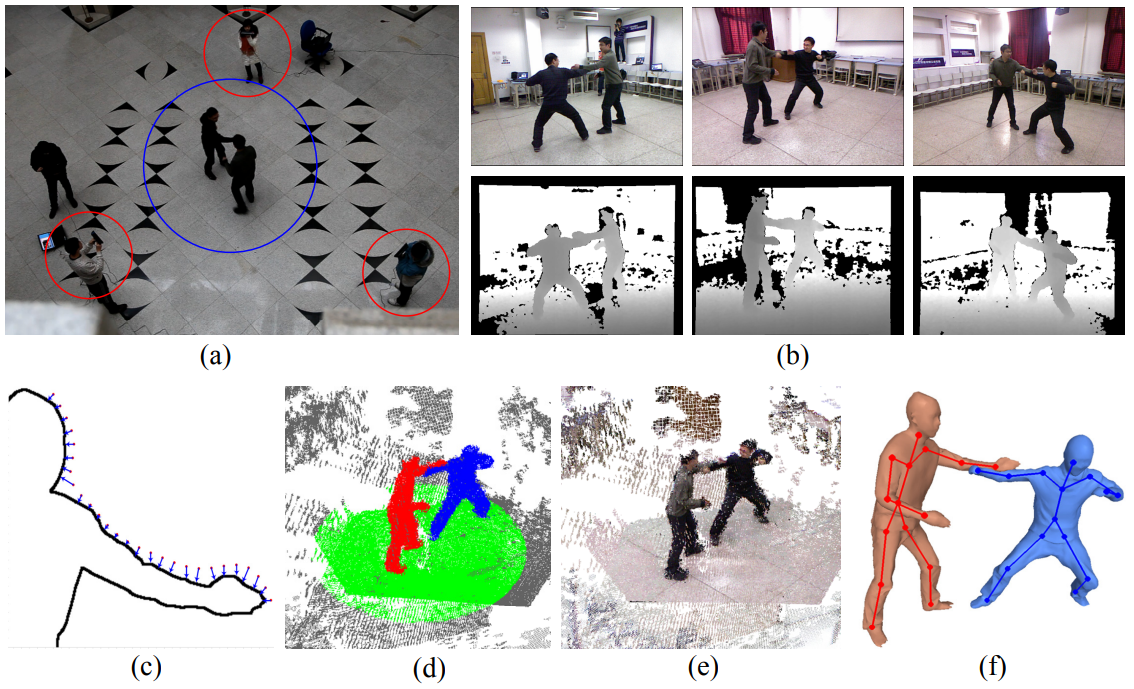
Fig 1. Overview of the processing pipeline. (a) overhead view of typical recording setup: three camera operators (circled in red) film the moving people in the center (blue); (b) input to the algorithm - RGB images and the depth images from three views; (c) 2D illustration of geometric matching of Kinect points to model vertices (Sect. 4.2); (d) segmented RGBZ point cloud - color labels correspond to background, ground plane (green) and interacting humans (red,blue); (e) Registered RGBZ point cloud from all cameras; (f) reconstructed surface models and skeletons.
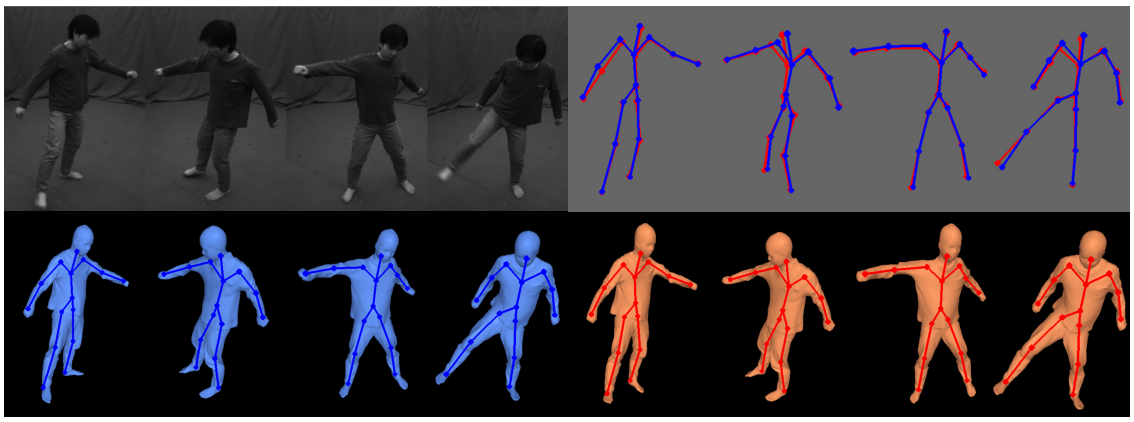
Fig 2. Comparison with multi-view video tracking (MVT) approach on the “Rolling” sequence. The top left are four input images of the multi-view video sequence. The top right shows the close overlap of the two skeletons tracked with MVT (blue) and our Kinect-based approach (red). The bottom left is the reconstructed surface with the skeleton using MVT and the bottom right is the results from our approach. Quantitative and visual comparisons show that MVT-based and Kinect-based reconstructions are very similar.
Citation
Ye, Genzhi, Yebin Liu, Nils Hasler, Xiangyang Ji, Qionghai Dai, and Christian Theobalt. "Performance capture of interacting characters with handheld kinects." In European Conference on Computer Vision, pp. 828-841. Springer, Berlin, Heidelberg, 2012.
@inproceedings{ye2012performance,
title={Performance capture of interacting characters with handheld kinects},
author={Ye, Genzhi and Liu, Yebin and Hasler, Nils and Ji, Xiangyang and Dai, Qionghai and Theobalt, Christian},
booktitle={European Conference on Computer Vision},
pages={828--841},
year={2012},
organization={Springer}
}