ECCV 2022
AvatarCap: Animatable Avatar Conditioned Monocular Human Volumetric Capture
Zhe Li, Zerong Zheng, Hongwen Zhang, Chaonan Ji, Yebin Liu
Tsinghua University
Abstract
To address the ill-posed problem caused by partial observations in monocular human volumetric capture, we present AvatarCap, a novel framework that introduces animatable avatars into the capture pipeline for high-fidelity reconstruction in both visible and invisible regions. Our method firstly creates an animatable avatar for the subject from a small number (~20) of 3D scans as a prior. Then given a monocular RGB video of this subject, our method integrates information from both the image observation and the avatar prior, and accordingly recon-structs high-fidelity 3D textured models with dynamic details regardless of the visibility. To learn an effective avatar for volumetric capture from only few samples, we propose GeoTexAvatar, which leverages both geometry and texture supervisions to constrain the pose-dependent dynamics in a decomposed implicit manner. An avatar-conditioned volumetric capture method that involves a canonical normal fusion and a reconstruction network is further proposed to integrate both image observations and avatar dynamics for high-fidelity reconstruction in both observed and invisible regions. Overall, our method enables monocular human volumetric capture with detailed and pose-dependent dynamics, and the experiments show that our method outperforms state of the art.
[arXiv] [Code]
Fig 1. Overview. We present AvatarCap that leverages an animatable avatar learned from only a small number (∼20) of scans for monocular human volumetric capture to realize high-fidelity reconstruction regardless of the visibility.
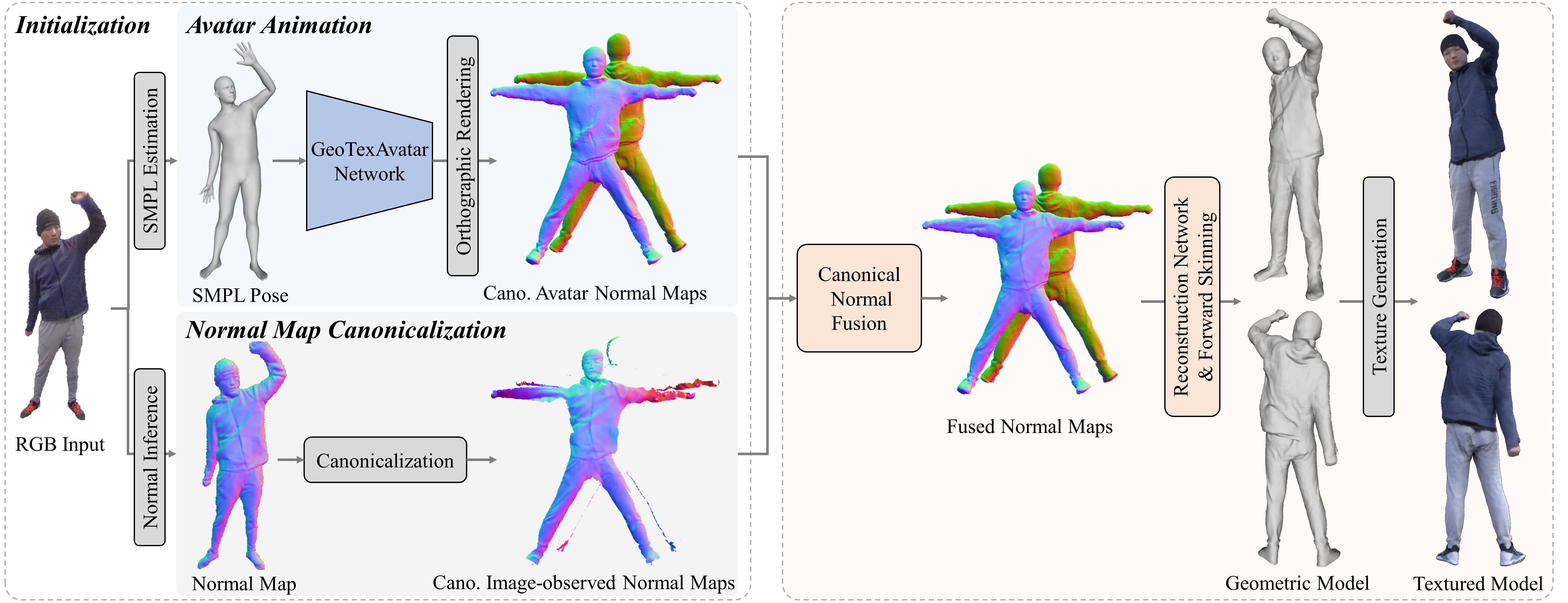
Fig 2. Avatar-conditioned voluemtric capture pipeline. Given a RGB image from the monocular video, we firstly infer the SMPL pose and normal map. Then the pose-driven GeoTexAvatar generates and renders canonical avatar normal maps, while the image-observed normal map is warped into the canonical space. The canonical normal fusion integrates both avatar and observed normals together and feeds the fused normal maps into the reconstruction network to output a high-fidelity 3D human model. Finally, a high-resolution texture is generated using the GeoTexAvatar network.
Results
Fig 3. Volumetric captured results of our method. We demonstrate monocular color input, geometric and textured reconstructed results, respectively.
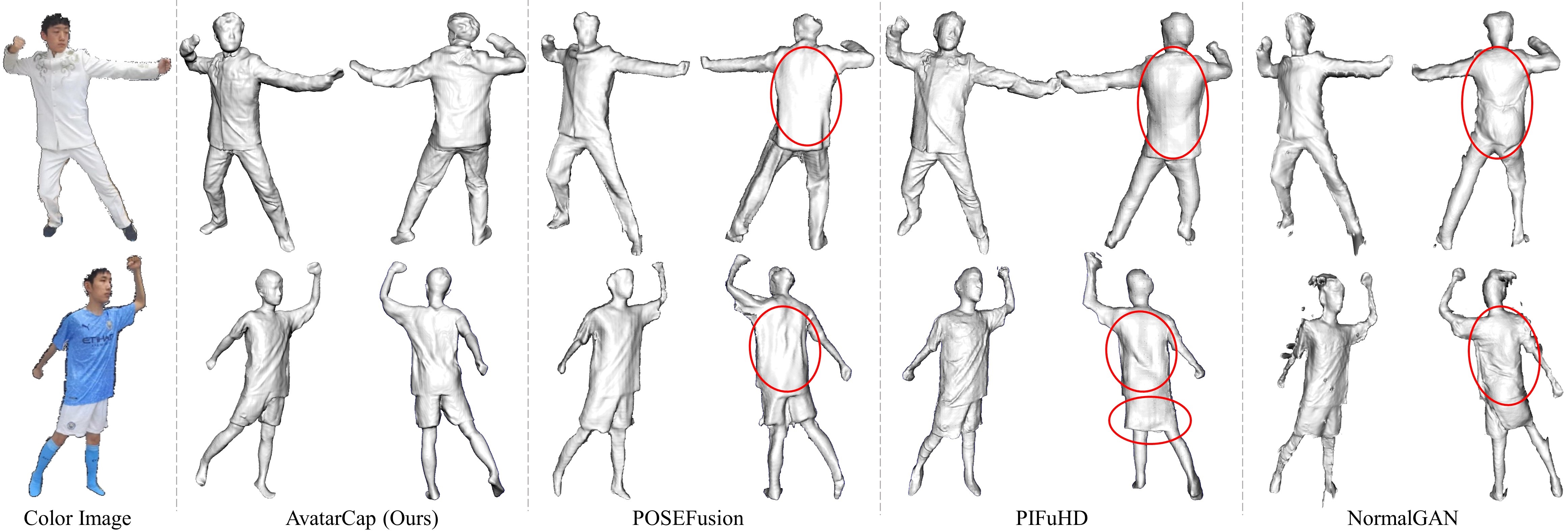
Fig 4. Qualitative comparison against monocular volumetric capture methods. We show reconstructed results of our method (AvatarCap), POSEFusion, PIFuHD and NormalGAN. And our method outperforms others on the capture of pose-dependent dynamics in the invisible regions (red circles).
Fig 5. Qualitative comparison against animatable avatar methods. We show animated results of our method (also with high-quality texture), SCANimate, SCALE and POP. And our method shows the superiority on the modeling of wrinkles (solid circles) and pose-dependent cloth tangential motions (dotted circles).
Technical Paper

Demo Video
Supplementary Material

Citation
Zhe Li, Zerong Zheng, Hongwen Zhang, Chaonan Ji, Yebin Liu. "AvatarCap: Animatable Avatar Conditioned Monocular Human Volumetric Capture". ECCV 2022
@InProceedings{li2022avatarcap,
title={AvatarCap: Animatable Avatar Conditioned Monocular Human Volumetric Capture},
author={Li, Zhe and Zheng, Zerong and Zhang, Hongwen and Ji, Chaonan and Liu, Yebin},
booktitle={European Conference on Computer Vision (ECCV)},
month={October},
year={2022},
}