ManVatar : Fast 3D Head Avatar Reconstruction Using Motion-Aware Neural Voxels
Yuelang Xu, Lizhen Wang, Xiaochen Zhao, Hongwen Zhang, Yebin Liu
Tsinghua University
Abstract
With NeRF widely used for facial reenactment, recent methods can recover photo-realistic 3D head avatar from just a monocular video. Unfortunately, the training process of the NeRF-based methods is quite time-consuming, as MLP used in the NeRF-based methods is inefficient and requires too many iterations to converge. To overcome this problem, we propose ManVatar, a fast 3D head avatar reconstruction method using Motion-Aware Neural Voxels. ManVatar is the first to decouple expression motion from canonical appearance for head avatar, and model the expression motion by neural voxels. In particular, the motionaware neural voxels is generated from the weighted concatenation of multiple 4D tensors. The 4D tensors semantically correspond one-to-one with 3DMM expression bases and share the same weights as 3DMM expression coefficients. Benefiting from our novel representation, the proposed ManVatar can recover photo-realistic head avatars in just 5 minutes (implemented with pure PyTorch), which is significantly faster than the state-of-the-art facial reenactment methods.

Fig 1.We propose ManVatar, a fast 3D head avatar reconstruction method. Given a monocular video, our method can recover photo-realistic head avatar in 5 minutes.
Overview
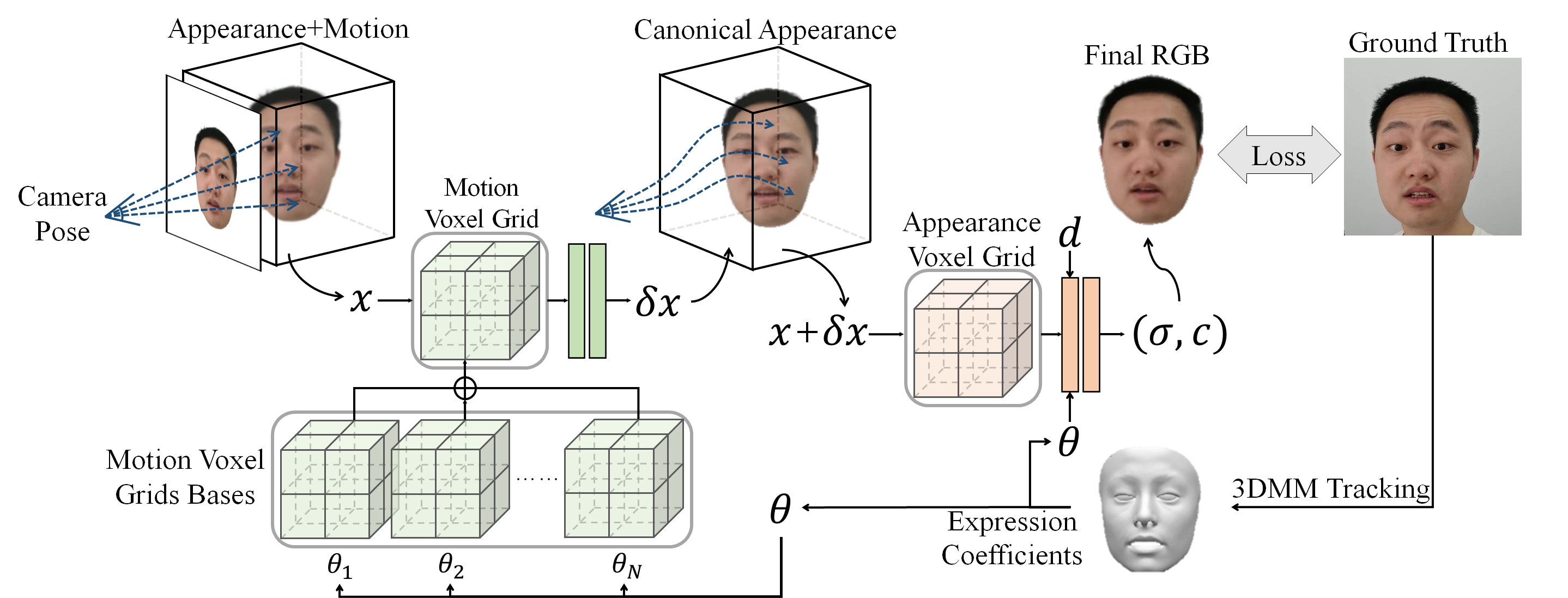
Fig 2. Overview. Given a portrait video, we first track the expression and head pose using a 3DMM template. After the pre-processing, given expression coefficients, we use motion voxel grid bases to represent motions caused by each expression basis and sum them weighted as an entire motion voxel grid. The entire motion voxel grid and the following 2-layer MLP will then transfer an input point \( x \) to \( x + \delta x \) by adding all expression-related deformations. Finally, we will query point \( x + \delta x \) in the appearance voxel grid and generate a final portrait image using volumetric rendering.
Results
Fig 3. Training Process. We illustrate the training process of our method ManVatar.
Fig 3. Training Speed Comparisons. We make qualitative comparisons on training speed among NeRFace, NeRFBlendShape and our ManVatar. Our model converges rapidly within the first 2 minutes.

Fig 4. Qualitative comparisons between ManVatar and other three state-of-the-art methods on self re-animation task. From left to right: IMAvatar, Deep Video Portraits (DVP), NeRFac, ManVatar and Ground Truth. Our approach is able to converge and learn details within a short time.

Fig 4. Qualitative results of ManVatar and three other state-of-the-art methods on facial reenactment task. From left to right: Deep Video Portraits (DVP), IMAvatar, NeRFace and ManVatar.
Demo Video